| |||
|
Últimos post!!!
Los ácidos nucleicos, estructura y función
Los ácidos nucleicos, estructura y función Algo de historia “Hemos encontrado el secreto de la vida”, se escuchó un 28 de Febrero...

miércoles, 6 de diciembre de 2017
Los ácidos nucleicos, estructura y función

Expresión génica
Expresión génica
El ADN es el material genético de todos los organismos de la Tierra. Cuando se transmite de padres a hijos, el ADN puede determinar algunas de las características de los hijos (como el color de sus ojos o de su cabello). Pero, ¿cómo puede la secuencia de una molécula de ADN realmente tener efecto sobre las características de un ser humano o de cualquier otro organismo? Por ejemplo, ¿cómo puede la secuencia de nucléotidos (As, Ts, Cs y Gs) del ADN de las plantas de chícharos de Mendel determinar el color de sus flores?
Los genes especifican productos funcionales (como proteínas)
Una molécula de ADN no solo es una larga y aburrida cadena de nucleótidos. En realidad, se divide en unidades funcionales llamadas genes. Cada gen proporciona las instrucciones para formar un producto funcional, o sea, una molécula necesaria para desempeñar un trabajo en la célula. En muchos casos, el producto funcional es una proteína. Por ejemplo, en el experimento de Mendel, el gen del color de las flores tiene las instrucciones para hacer una proteína que ayuda a producir moléculas coloridas (pigmentos) en los pétalos de las flores.

Imagen basada en los datos experimentales reportados por Hellens et aly en una figura similar de Reece et al.
El producto funcional de la mayoría de los genes son proteínas, o para ser más exactos, polipéptidos. El término polipéptido es solo una palabra para designar una cadena de aminoácidos. Aunque muchas proteínas se conforman de un solo polipéptido, algunas están hechas de varios polipéptidos. Los genes que especifican polipéptidos se conocen como genes codificantes de proteínas.
No todos los genes codifican proteínas. Por el contrario, algunos proporcionan instrucciones para producir moléculas de ARN funcionales, como los ARN de transferencia y los ARN ribosomales que desempeñan papeles en la traducción.
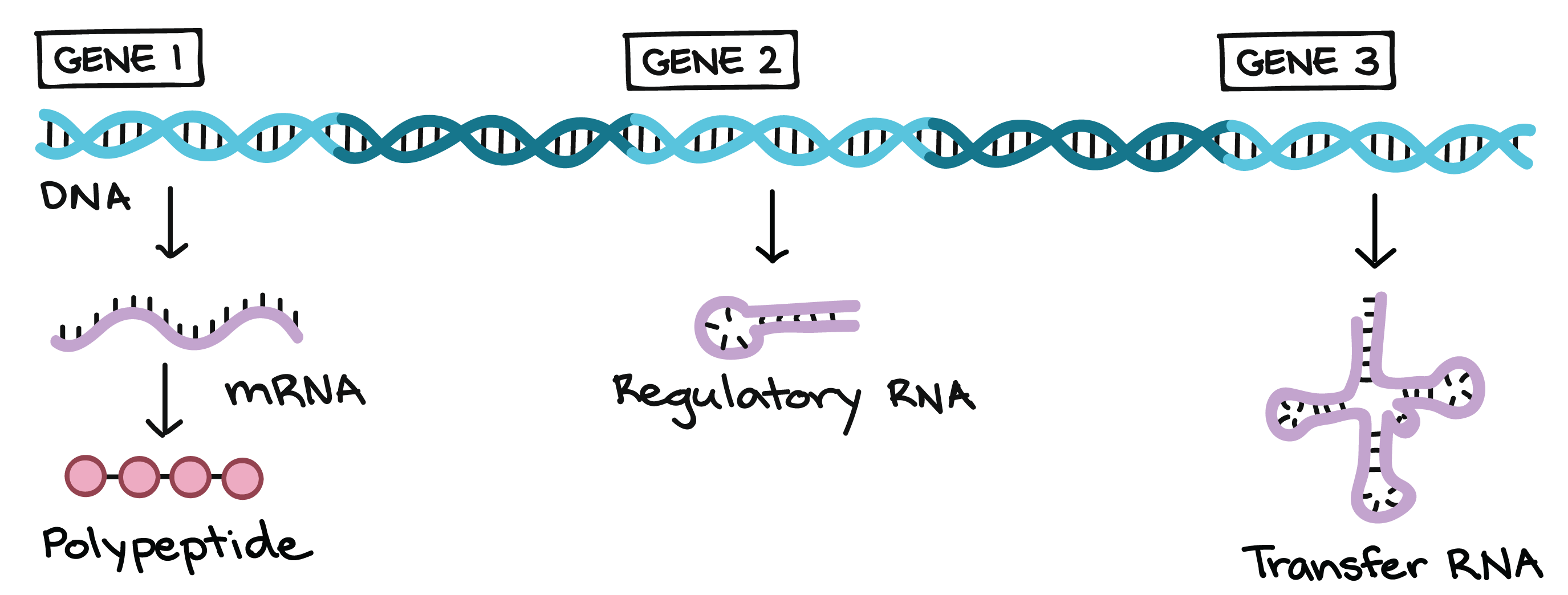
¿Cómo puede la secuencia de ADN de un gen especificar una proteína en particular?
Muchos genes proporcionan instrucciones para producir polipéptidos. ¿Cómo dirige exactamente el ADN la construcción de un polipéptido? Este proceso consta de dos pasos: transcripción y traducción.
- En la transcripción, la secuencia de ADN de un gen se copia para obtener una molécula de ARN. Este proceso es llamado transcripción porque implica reescribir, o trancribir, la secuencia de ADN en un "alfabeto" de ARN similar. En eucariontes, la molécula de ARN debe someterse a un procesamiento para convertirse en un ARN mensajero (ARNm) maduro.
- En la traducción, la secuencia de ARNm se decodifica para especificar la secuencia de aminoácidos de un polipéptido. El nombre traducción refleja que la secuencia de nucleótidos del ARNm se debe traducir al "idioma", completamente diferente, de los aminoácidos.

Por lo tanto, durante la expresión de un gen codificante de proteína, la información fluye de ADN ARN proteína. Este flujo de información se conoce como el dogma central de la biología molecular. Los genes no codificantes (genes que producen ARN funcionales) también se transcriben para producir ARN, pero este ARN no se traduce en un polipéptido. Para cualquier tipo de gen, el proceso de pasar de ADN a producto funcional se conoce como expresión génica.
Transcripción
En la transcripción, una cadena del ADN que compone al gen, llamada cadena no codificante, funciona como molde para que una enzima llamada ARN polimerasa sintetice una cadena de ARN correspondiente (complementaria). Esta cadena de ARN se llama transcrito primario.

El transcrito primario tiene la misma secuencia de información que la cadena de ADN que no se transcribió, generalmente llamada cadena codificante. Sin embargo, el transcrito primario y la cadena codificante no son idénticos debido a ciertas diferencias bioquímicas entre el ADN y el ARN. Una diferencia importante es que las moléculas de ARN no contienen la base timina (T). En lugar de timina, las moléculas de ARN utilizan una base similar llamada uracilo(U). El uracilo, al igual que la timina, forma pareja con la adenina.

Transcripción y procesamiento de ARN: eucariontes frente a bacterias
En bacterias, el transcrito primario puede servir directamente como ARN mensajero o ARNm. El ARN mensajero obtiene su nombre por el hecho de actuar como mensajero entre el ADN y los ribosomas. Los ribosomas son las estructuras de ARN y proteínas en el citosol donde se forman las proteínas.
En eucariontes (como los seres humanos), el transcrito primario debe someterse a algunos pasos extra para convertirse en un ARNm maduro. Durante el procesamiento, se añaden casquetes en ambos extremos del ARN y se eliminan cuidadosamente algunas de sus porciones en un proceso conocido como empalme. Estos pasos no ocurren en bacterias.

El lugar donde ocurre la transcripción también es diferente entre procariontes y eucariontes. La transcripción eucarionte ocurre en el núcleo, donde se almacena el ADN, mientras que la síntesis de proteínas ocurre en el citosol. Debido a esto, el ARNm eucarionte debe ser exportado del núcleo antes de que pueda traducirse en un polipéptido. Las células procariontes, por otra parte, no tienen núcleo, por lo que la transcripción y la traducción se llevan a cabo en el citosol.
Traducción
Después de la transcripción (y de algunos pasos de procesamiento en eucariontes), la molécula de ARNm está lista para dirigir la síntesis de proteínas. El proceso de usar información de un ARNm para producir un polipéptido se llama traducción.
El código genético
Durante la traducción, la secuencia de nucleótidos de un ARNm se traduce en la secuencia de aminoácidos de un polipéptido. Específicamente, los nucleótidos del ARNm se leen en tripletes (grupos de tres) llamados codones. Existen codones que especifican aminoácidos. Uno de esos codones es un codón de "inicio" que señala dónde comienza la traducción. El codón de inicio codifica para el aminoácido metionina, por lo que la mayoría de los polipéptidos comienzan con este aminoácido. Otros tres codones de "terminación" indican el final de un polipéptido. Estas relaciones se llaman código genético.
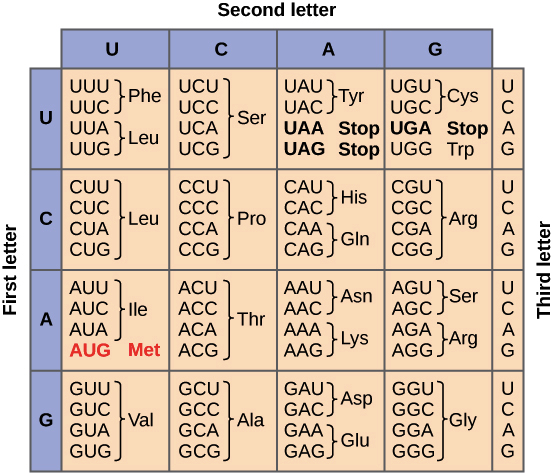
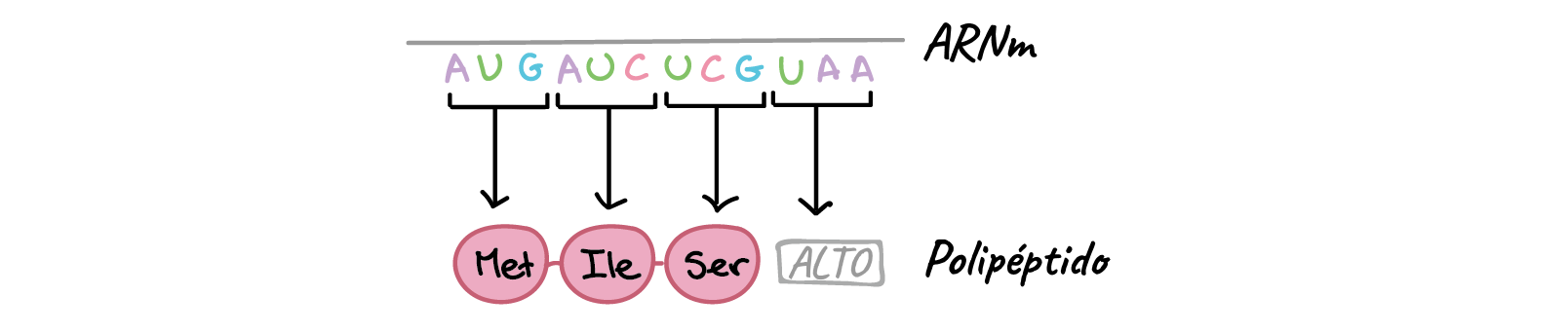
Los pasos de la traducción
La traducción ocurre dentro de estructuras conocidas como ribosomas. Los ribosomas son máquinas moleculares cuya función es construir polipéptidos. Una vez que un ribosoma se monta sobre un ARNm y encuentra el codón de "inicio", se desplazará rápidamente por el ARNm un codón a la vez. Al avanzar, construirá poco a poco una cadena de aminoácidos que refleja exactamente la secuencia de codones en el ARNm.
¿Cómo "sabe" el ribosoma qué aminoácido insertar para cada codón? Pues resulta que esta correspondencia no la hace el ribosoma por sí mismo. En realidad, depende de un grupo de moléculas de ARN especializadas llamadas ARN de transferencia (ARNt). Cada ARNt tiene tres nucleótidos que sobresalen en un extremo y pueden reconocer (complementar sus bases con) uno o unos cuantos codones en particular. En el otro extremo, el ARNt transporta un aminoácido: específicamente, el aminoácido que corresponde con esos codones.

Hay muchos ARNt flotando en una célula, pero solo el ARNt que coincide (cuyas bases se complementan) con el codón que se lee en ese momento puede unirse y suministrar su carga de aminoácido. Una vez que el ARNt está perfectamente unido a su codón correspondiente en el ribosoma, su aminoácido se añadirá al final de la cadena polipeptídica.

Este proceso se repite muchas veces y el ribosoma se mueve sobre el ARNm un codón a la vez. La cadena de aminoácidos se construye pieza por pieza con una secuencia de aminoácidos que coincide con la secuencia de codones en el ARNm. La traducción termina cuando el ribosoma alcanza un codón de terminación y libera el polipéptido.
¿Qué sucede después?
Una vez terminado el polipéptido, este puede ser procesado, modificado, combinado con otros polipéptidos o enviado a algún destino en específico dentro o fuera de la célula. En última instancia, este polipéptido realizará un trabajo específico para la célula o el organismo, tal vez como molécula de señalización, algún elemento estructural o una enzima.
Recapitulación:
- El ADN se divide en unidades funcionales llamadas genes, los cuales pueden especificar polipéptidos (proteínas y subunidades proteicas) o ARN funcionales (como los ARNt y ARNr).
- La información de un gen se utiliza para construir un producto funcional en un proceso llamado expresión génica.
- Los genes que codifican polipéptidos se expresan en dos pasos. En este proceso, la información fluye de ADN ARN proteína, lo que constituye una relación direccional conocida como el dogma central de la biología molecular.
- Transcripción: una cadena del ADN del gen se copia en ARN. En eucariontes, el transcrito de ARN se debe someter a pasos adicionales de procesamiento para convertirse en un ARN mensajero maduro (ARNm).
- Traducción: la secuencia de nucleótidos del ARNm se decodifica para especificar la secuencia de aminoácidos de un polipéptido. Este proceso ocurre dentro de un ribosoma y requiere de moléculas adaptadoras llamadas ARNt.
- Durante la traducción, los nucleótidos del ARNm se leen en grupos de tres llamados codones. Cada codón especifica un aminoácido en particular o una señal de alto. Este conjunto de relaciones se conoce como código genético.
Suscribirse a:
Comentarios (Atom)
-
Hola amigos blogeros! los invito a ver el contenido de compañeros míos, donde también aprenderán de muchos cursos mas. Jesús Suarez Fer...
-
La Medicina 2.0 es un nuevo concepto sobre cómo se debe hacer Medicina, es el futuro de la práctica médica. Medicina 2.0 es algo más que un...
-
La aparición de herramientas web 2.0 , para muchos identificada por la aparición de las redes sociales y surgimiento de blogs, que volvi...
-
Zotero es uno de los gestores de referencias bibliográficas , libre, abierto y gratuito desarrollado por el Center for History and New M...
-
Expresión génica El ADN es el material genético de todos los organismos de la Tierra. Cuando se transmite de padres a hijos, el AD...
-
Los ácidos nucleicos, estructura y función Algo de historia “Hemos encontrado el secreto de la vida”, se escuchó un 28 de Febrero...
-
œ PROPORCIONALIDAD, TANTO POR CIENTO Y REGLA DE TRES SIMPLE 1. El precio de un refrigerador ...
-
1 - Un estudiante responde al azar a dos preguntas de verdadero o falso. Escriba el espacio muestral de este experimento aleatorio. ...
-
 Classroom es una herramienta de gran utilidad para la experiencia de los estudiantes en las clases con sus docentes, gracias a este método ...
Classroom es una herramienta de gran utilidad para la experiencia de los estudiantes en las clases con sus docentes, gracias a este método ... -
En este vídeo de diapositivas veremos una primera parte del sistema numérico: Ademas de lo ya visto antes, haciéndole clic a las ...





{kind=link}